Начал писать эту статью довольно давно, но перед самой публикацией оказалось, что меня опередили соратники по профессии и выложили практически идентичный материал.
Поначалу я решил, что публиковать свою статью не буду, так как тему и без того прекрасно осветили более опытные коллеги. Михаил Шакин рассказал о 9-ти способах чистки запросов в KC, а Игорь Бакалов отснял видео об анализе неявных дублей. Однако, спустя какое-то время, взвесив все за и против, пришел к выводу, что возможно моя статья имеет право на жизнь и кому-то может пригодиться – не судите строго.
Если вам необходимо отфильтровать большую базу ключевых слов, состоящую из 200к или 2 миллионов запросов, то эта статья может вам помочь. Если же вы работаете с малыми семантическими ядрами, то скорее всего, статья не будет для вас особо полезной.
Рассматривать фильтрацию большого семантического ядра будем на примере выборки, состоящей из 1 миллиона запросов по юридической теме.
Что нам понадобится?
- Key Collector (Далее KC)
- Минимум 8гб оперативной памяти (иначе нас ждут адские тормоза, испорченное настроение, ненависть, злоба и реки крови в глазных капиллярах)
- Общие Стоп-слова
- Базовое знание языка регулярных выражений
Если вы совсем новичок в этом деле и с KC не в лучших друзьях, то настоятельно рекомендую ознакомиться с внутренним функционалом, описанным на официальных страницах сайта. Многие вопросы отпадут сами собой, также вы немножечко разберетесь в регулярках.
Итак, у нас есть большая база ключей, которые необходимо отфильтровать. Получить базу можно посредством самостоятельного парсинга, а также из различных источников, но сегодня не об этом.
Всё, что будет описано далее актуально на примере одной конкретной ниши и не является аксиомой! В других нишах часть действий и этапов могут существенно отличаться! Я не претендую на звание Гуру семантика, а лишь делюсь своими мыслями, наработками и соображениями на данный счет.
Оглавление
- Шаг 1. Удаляем латинские символы
- Шаг 2. Удаляем спец. Символы
- Шаг 3. Удаляем повторы слов
- Шаг 4. Удаляем фразы, состоящие из 1 и 7+ слов
- Шаг 5. Очистка неявных дублей
- Шаг 6. Фильтруем по стоп-словам
- Шаг 7. Удаляем 1 и 2 символьные «слова»
- Шаг 8. Удаляем фразы с числами
- Группировка/кластеризация фраз (опционально)
Шаг 1. Удаляем латинские символы
Удаляем все фразы, в которых встречаются латинские символы. Как правило, у таких фраз ничтожная частотка (если она вообще есть) и они либо ошибочны, либо не относятся к делу.
Все манипуляции с выборками по фразам проделываются через вот эту заветную кнопку

Далее выставляем настройки, указанные на скриншоте, и жахаем «применить».

Если вы взяли миллионное ядро и дошли до этого шага – то здесь глазные капилляры могут начать лопаться, т.к. на слабых компьютерах/ноутбуках любые манипуляции с крупным СЯ могут, должны и будут безбожно тормозить.
Выделяем/отмечаем все фразы и удаляем.
Шаг 2. Удаляем спец. Символы
Операция аналогична удалению латинских символов (можно проводить обе за раз), однако я рекомендую делать все поэтапно и просматривать результаты глазами, а не «рубить с плеча», т.к. порой даже в нише, о которой вы знаете, казалось бы, все, встречаются вкусные запросы, которые могут попасть под фильтр и о которых вы могли попросту не знать.

Небольшой совет, если у вас в выборке встречается множество хороших фраз, но с запятой или другим символом, просто добавьте данный символ в исключения и всё.
Еще один вариант (самурайский путь)
- Выгрузите все нужные фразы со спецсимволами
- Удалите их в KC
- В любом текстовом редакторе замените данный символ на пробел
- Загрузите обратно.
Теперь фразоньки чисты, репутация их отбелена и выборка по спец. символам их не затронет.
Шаг 3. Удаляем повторы слов
И снова воспользуемся встроенным в KC функционалом, применив правило

Тут и дополнить нечем – все просто. Убиваем мусор без доли сомнения.
Если перед вами стоит задача произвести жесткую фильтрацию и удалить максимум мусора, при этом пожертвовав какой-то долей хороших запросов, то можете все 3 первых шага объединить в один.
Выглядеть это будет так:

ВАЖНО: Не забудьте переключить «И» на «ИЛИ»!
Шаг 4. Удаляем фразы, состоящие из 1 и 7+ слов
Кто-то может возразить и рассказать о крутости однословников, не вопрос – оставляйте, но в большинстве случаев ручная фильтрация однословников занимает очень много времени, как правило соотношение хороший/плохой однословник – 1/20, не в нашу пользу. Да и вбить их в ТОП посредством тех методов, для которых я собираю такие ядра из разряда фантастики. Поэтому, поскрипывая сердечком отправляем словечки к праотцам.

Предугадываю вопрос многих, «зачем длинные фразы удалять»? Отвечаю, фразы, состоящие из 7 и более слов по большей части, имеют спамную конструкцию, не имеют частотку и в общей массе образуют очень много дублей, дублей именно тематических. Приведу пример, чтоб было понятней.

К тому же частотка у подобных вопросов настолько мала, что зачастую место на сервере обходится дороже, чем выхлоп от таких запросов. К тому же, если вы просмотрите ТОП-ы по длинным фразам, то прямых вхождений ни в тексте ни в тегах не найдете, так что использование таких длинных фраз в нашем СЯ – не имеет смысла.
Шаг 5. Очистка неявных дублей
Предварительно настраиваем очистку, дополняя своими фразами, указываю ссылку на свой список, если есть, чем дополнить – пишите, будем стремиться к совершенству вместе.

Если этого не сделать, и использовать список, любезно предоставленный и вбитый в программу создателями KC по умолчанию, то вот такие результаты у нас останутся в списке, а это, по сути, очень даже дубли.

Можем выполнить умную группировку, но для того, чтобы она отработала корректно – необходимо снять частотку. А это, в нашем случае не вариант. Т.к. Снимать частотку с 1млн. кеев, да пусть хоть со 100к – понадобится пачка приватных проксей, антикапча и очень много времени. Т.к. даже 20 проксей не хватит – уже через час начнет вылезать капча, как не крути. И займет это дело очень много времени, кстати, бюджет антикапчи тоже пожрет изрядно. Да и зачем вообще снимать частотку с мусорных фраз, которые можно отфильтровать без особых усилий?
Если же вы все-таки хотите отфильтровать фразы с умной группировкой, снимая частотности и поэтапно удаляя мусор, то расписывать процесс подробно не буду – смотрите видео, на которое я сослался в самом начале статьи.
Вот мои настройки по очистке и последовательность шагов

Шаг 6. Фильтруем по стоп-словам
На мой взгляд – это самый муторный пункт, выпейте чая, покурите сигаретку (это не призыв, лучше бросить курить и сожрать печеньку) и со свежими силами сядьте за фильтрацию семантического ядра по стоп-словам.
Не стоит изобретать велосипед и с нуля начинать составлять списки стоп-слов. Есть готовые решения. В частности, вот вам священный Грааль, в качестве основы более, чем пойдет.
Советую скопировать табличку в закорма собственного ПК, а то вдруг братья Шестаковы решат оставить «вашу прелесть» себе и доступ к файлику прикроют? Как говорится «Если у вас паранойя, это еще не значит, что за вами не следят…»
Лично я разгрупировал стоп-слова по отдельным файлам для тех или иных задач, пример на скриншоте.

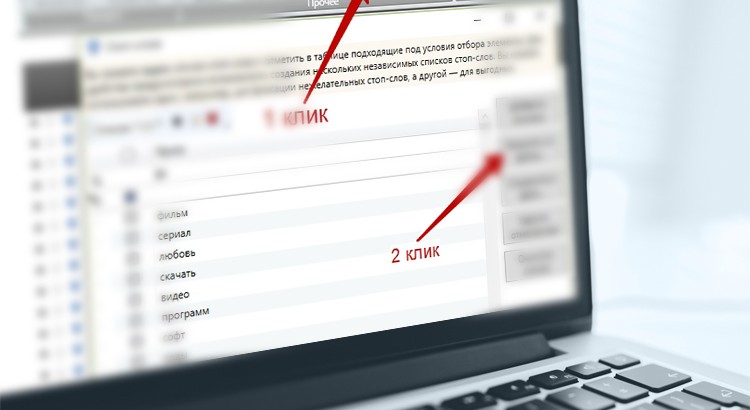
Файл «Общий список» содержит все стоп-слова сразу. В Кей Коллекторе открываем интерфейс стоп-слов и подгружаем список из файла.
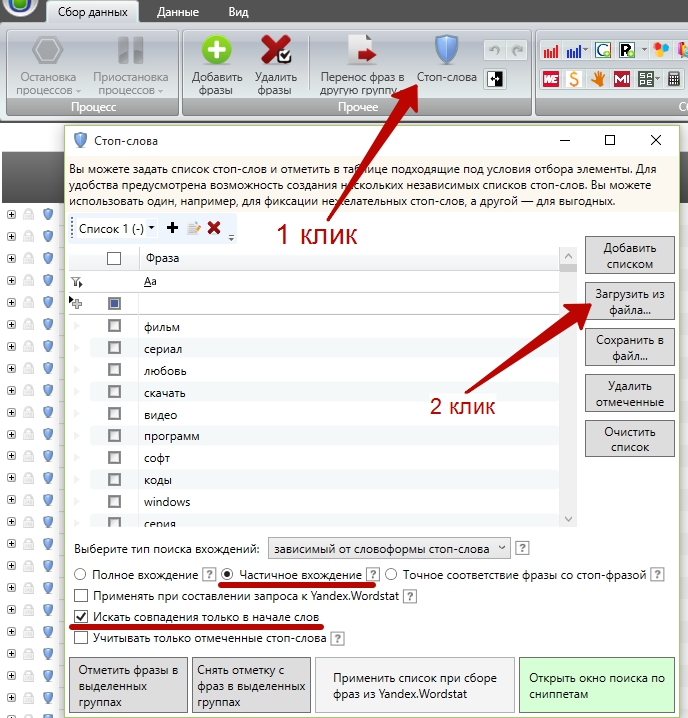
Я ставлю именно частичное вхождение и галочку в пункте «Искать совпадения только в начале слов». Данные настройки особенно актуальны при огромном объеме стоп-слов по той причине, что множество слов состоят из 3-4 символов. И если поставите другие настройки, то вполне можете отфильтровать массу полезных и нужных слов.
Если мы не поставим вышеуказанную галочку, то пошлое стоп-слово «трах» найдется в таких фразах как «консультация государственного страхования» , «как застраховать вклады» и т.д. и т.п. Вот ещё пример, по стоп слову «рб» (республика Беларусь) будет отмечено огромное кол-во фраз, по типу «возмещение ущерба консультация», «предъявление иска в арбитражном процессе» и т.д. и т.п.
Иными словами — нам нужно, чтобы программа выделяла только фразы, где стоп-слова встречаются в начале слов. Формулировка ухо режет, но из песни слов не выкинешь.
Отдельно замечу, что данная настройка приводит к существенному увеличению времени проверки стоп слов. При большом списке процесс может занять и 10 и 40 минут, а все из-за этой галочки, которая увеличивает время поиска стос-слов во фразах в десять, а то и более раз. Однако это наиболее адекватный вариант фильтрации при работе с большим семантическим ядром.
После того как мы прошлись по базовым списком рекомендую глазами просмотреть не попали ли под раздачу какие-то нужные фразы, а я уверен, так оно и будет, т.к. общие списки базовых стоп-слов, не универсальны и под каждую нишу приходится прорабатывать отдельно. Вот тут и начинаются «танцы с бубном.
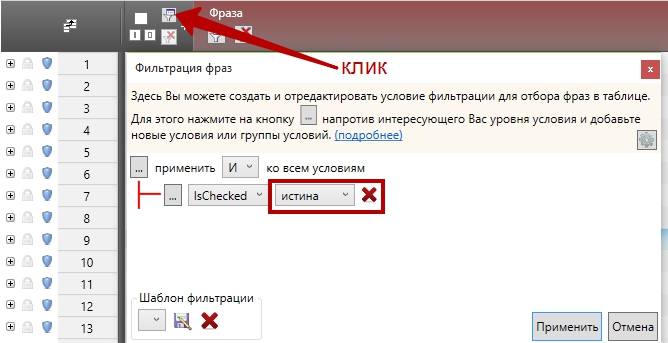
Оставляем в рабочем окне только выделенные стоп слов, делается это вот так.
Затем нажимаем на «анализ групп», выбираем режим «по отдельным словам» и смотрим, что лишнего попало в наш список из-за неподходящих стоп-слов.
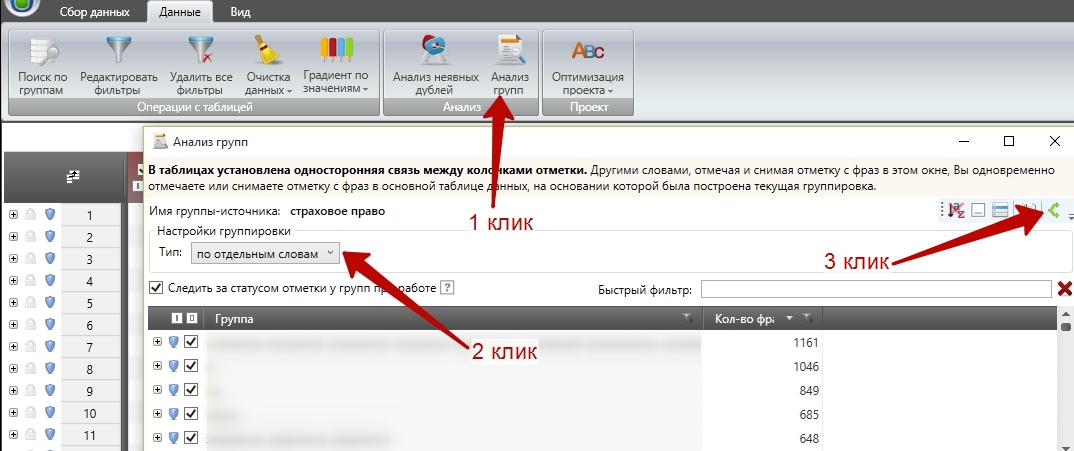
Удаляем неподходящие стоп-слова и повторяем цикл. Таким образом через некоторое время мы «заточим» универсальный общедоступный список под наши нужды. Но это еще не все.
Теперь нам нужно подобрать стоп-слова, которые встречаются конкретно в нашей базе. Когда речь идет об огромных базах ключевиков, там всегда есть какой-то «фирменный мусор», как я его называю. Причем это может быть совершенно неожиданный набор бреда и от него приходится избавляться в индивидуальном порядке.
Для того, чтобы решить эту задачку мы снова прибегнем к функционалу Анализа групп, но на этот раз пройдемся по всем фразам, оставшимся в базе, после предыдущих манипуляций. Отсортируем по количеству фраз и глазами, да-да-да, именно ручками и глазами, просмотрим все фразы, до 30-50 в группе. Я имею в виду вторую колонку «кол-во фраз в группе».
Слабонервных поспешу предупредить, на первый взгляд бесконечный ползунок прокрутки», не заставит вас потратить неделю на фильтрацию, прокрутите его на 10% и вы уже дойдете до групп, в которых содержится не более 30 запросов, а такие фильтровать стоит только тем, кто знает толк в извращениях.
Прямо из этого же окна мы можем добавлять весь мусор в стоп слова (значок щита слева от селектбокса).
Дополнительный совет: Рекомендую просматривать глазами словоформы. И вместо того, чтобы добавлять все, добавлять лишь корень, приведу пример:
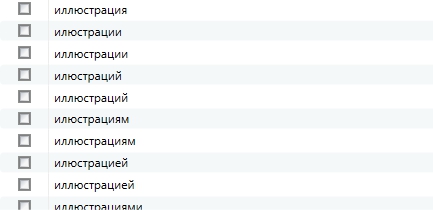
Вместо того, чтобы добавлять все эти стоп слова (а их гораздо больше, просто я не хотел добавлять длиннющий по вертикали скриншот), мы изящно добавляем корень «фильтрац» и сразу отсекаем все вариации. В результате наши списки стоп-слов не будут разрастаться до огромных размеров и что самое главное, мы не будем тратить лишнее время на их поиск. А на больших объемах — это очень важно.
Шаг 7. Удаляем 1 и 2 символьные «слова»
Не могу подобрать точное определение к данному типу сочетания символов, поэтому обозвал «словами». Возможно, кто-то из прочитавших статью подскажет, какой термин подойдет лучше, и я заменю. Вот такой вот я косноязычный.
Многие спросят, «зачем вообще это делать»? Ответ прост, очень часто в таких массивах ключевых слов встречается мусор по типу:

Общий признак у таких фраз — 1 или 2 символа, не имеющие никакого смысла (на скриншоте пример с 1 символм). Вот это мы и будем фильтровать. Здесь есть свои подводные камни, но обо всем по порядку.
Как убрать все слова, состоящие из 2-х символов?
Для этого используем регулярку

Дополнительный совет: Всегда сохраняйте шаблоны регулярок! Они сохраняются не в рамках проекта, а в рамках KC в целом. Так что будут всегда под рукой.
(^|\s+)(..)(\s+|$) или же (^|\s)[a-zа-я]{1,2}(\s|$)
( ст | фз | ук | на | рф | ли | по | ст | не | ип | до | от | за | по | из | об )
$рф
Вот мой вариант, кастомизируйте под свои нужды.
Вторая строка – это исключения, если их не вписать, то все фразы, где встречаются сочетания символов из второй строки формулы, попадут в список кандидатов на удаление.
Третья строка исключает фразы, в конце которых встречается «рф», т.к. зачастую это нормальные полезные фразы.
Отдельно хочу уточнить, что вариант (^|\s+)(..)(\s+|$) будет выделять все – в том числе и числовые значения. Тогда как регулярка (^|\s)[a-zа-я]{1,2}(\s|$) – затронет лишь буквенные, за неё отдельное спасибо Игорю Бакалову.
Применяем нашу конструкцию и удаляем мусорные фразы.
Как убрать все слова, состоящие из 1 символа?
Здесь все несколько интересней и не так однозначно.
Сначала я попробовал применить и модернизировать предыдущий вариант, но в результате выкосить весь мусор не получилось, тем не менее – многим подойдет именно такая схема, попробуйте.

(^|\s+)(.)(\s+|$)
( с | в | и | я | к | у | о )
(^с |^в |^у)
Традиционно – первая строка сама регулярка, вторая – исключения, третья – исключает те фразы, в которых перечисленные символы встречаются в начале фразы. Ну, оно то и логично, ведь перед ними не стоит пробела, следовательно, вторая строка не исключит их присутствие в выборке.
А вот второй вариант при помощи которого я и удаляю все фразы с односимвольным мусором, простой и беспощадной, который в моем случае помог избавиться от очень большого объема левых фраз.

( й | ц | е | н | г | ш | щ | з | х | ъ | ф | ы | а | п | р | л | д | ж | э | ч | м | т | ь | б | ю )
Москв
Я исключил из выборки все фразы, где встречается «Москв», потому что было очень много фраз по типу:

а мне оно нужно сами догадываетесь для чего.
Шаг 8. Удаляем фразы с числами
На мой взгляд этот шаг наиболее индивидуальный и творческий, в различных нишах настройки отличаются кардинально. В частности в e-commerce подобная чистка удалит все фразы с числами, например, «Товар какой-то по цене такой-то» — порой это кластер довольно жирных фраз с низкой конкуренцией, по которым можно и нужно делать посадочные. Чтоб не быть голословным, вот пример:

Поэтому сначала подумайте как применить фильтрацию фраз с числами в случае с вашей темой и базой запросов, а потом приступайте.
Вот как я удалил все ненужное в нашем случае

Расписывать не буду – тут и так все очевидно. Единственное, на чем заострю внимание — «\d+» это регулярное выражение, при помощи которого мы выделяем все фразы, содержащие числовые значения. Также можно использовать «[0-9]+» как вашей душе угодно.
Расскажу, как под ту или иную нишу подобрать свой вариант.
- Выделяем все фразы, содержащие числовые значения через вышеуказанные регулярки.
- Глазами просматриваем результат и выделяем интенты нужных фраз – то есть, какие-то общие признаки. После этого добавляем их в исключения (смотрите мой скриншот выше) и так несколько раз, пока в выдаче не останется один мусор.
- Какая-то часть белых и пушистых фраз может и останется – но я придерживаюсь правила: лучше удалить 1 хорошую фразу, чем оставить 10 плохих.
ГОТОВО! В результате из базы ключевых слов в 1 миллион у меня получилось ядро на 230к. Конечно, если просмотреть глазами, там можно найти нелепые и мусорные фразы, но не имеющие общих признаков, а в ручную фильтровать такие массивы — это какой-то Сешоный АдЪ.
Для тех, кто все-таки решил кластеризовать/сгрупировать фразы и не хочет пользоваться платными сервисами, опишу свой вариант.
Группировка/кластеризация фраз (опционально)
Это самая ресурсоемкая процедура и если ваш дорг…. ой, то есть движок не поддерживают работу с подобной структурой, то забудьте, забейте и радуйтесь – первые 8 шагов уже отфильтровали львиную долю мусора.
Далее мы будем обрабатывать полученный результат, а не продолжать очистку.
Способ 1
Существуют тривиальные способы фильтрации, позволяющие на автомате сгруппировать фразы по отдельным словам (упоминал в шаге 6), а также по составу фраз. В большинстве случаев для кластеризации запросов нам вполне подойдет режим «по составу фраз».
Обычно я выставляю следующие настройки.
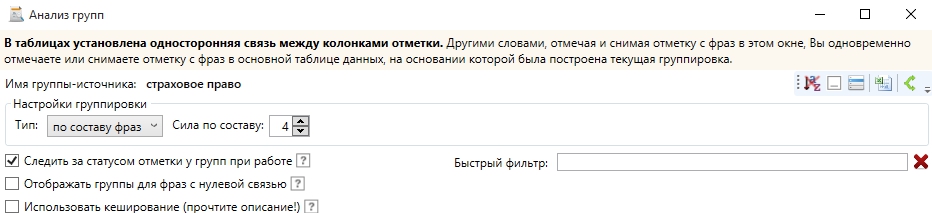
Процедура анализа может занять очень много времени, так что рекомендую сразу же определиться с силой по составу фраз. Что для этого надо?
- Рассортируйте фразы по алфавиту (просто нажмите на столбик фраза)
- Создайте пустую группу
- Выделите 10-30к запросов
- Скопируйте их в созданную группу
- Попробуйте разные варианты силы по составу фраз на данном объеме.
Когда найдете оптимальный показатель приступайте к группировке всего ядра.
Еще несколько слов о «силе по составу». Для тех, кто не совсем понимает, что это такое и как быть. Данная цифра отвечает за количество слов, которые должны пересекаться во фразах для того, чтобы те были объединены в группы. Иными словами чем выше показатель — тем меньше будет групп. Вряд ли вы найдете множество фраз в которых повторяет 7 и более слов — это скорее дубли, а не какие-то группы.
В принципе — оптимально ставить 3-4 (четверку ставьте для особо чистых и жирных ядер).
После того, как программа закончит обрабатывать данные делаем выгрузку в Excel. Готово!
Отдельно хочу заметить — что это и близко не тоже самое, что кластеризация запросов в платных сервисах и для особо белых проектов подобная группировка будет слишком топорной и вряд ли окажется полезной. Здесь все-же работа с объемом ставится превыше качества. Чтобы сгруппировать такое ядро в любом из доступных сервисов придется поставить зубы на полку и перейти на «Доширак», а то и вовсе на «Мивину».
Способ 2
В некоторых случаях нам нужно выделить группы из ядра не по составу фраз, а по каким-то собственным, нетривиальным задачам.
Представим, что нам нужно получить все фразы для раздела сайта вопрос-ответ по теме «аренда земли». Иными словами все вопросительные фразы. Здесь нам придется включить голову и вернуться к функционалу регулярок, но уже в другом ключе, особые знания регулярных выражений не понадобятся.
Собираем все части речи, присущие нашему кластеру запросов, кстати, вот мой список из конкретного примера, может кому-то пригодится. И выставляем вот такие настройки.

В результате получаем нужные нам фразы, которые мы можем перенести в отдельную группу или просто экспортировать.
Рекомендую вот такие шаблоны регулярок всегда сохранять отдельно и в результате для любого проекта у вас будет ряд универсальных решений, позволяющих делать быстрые выборки фраз.
Надеюсь данный материал окажется для кого-нибудь полезным. Если у вас есть вопросы или дополнения — пишите в комментариях.
P.S. Хотел написать, «подписывайтесь на наш сайт», но мы до сих пор не прикрутили RSS и рассылку, так-что добавляйте бложек в закладки и ставьте лайки на Facebook 🙂

